Veri Ön İşleme Adımları
Veri ön işleme, veri bilimi ve makine öğrenimi projelerinde kritik bir aşamadır. Bu süreç, verilerin modelleme için uygun hale getirilmesini içerir. Bu bölümde, Scikit-learn kütüphanesinin sunduğu popüler Iris veri seti üzerinde bazı temel veri ön işleme adımlarını gerçekleştireceğiz.
İlk olarak, gerekli kütüphaneleri içe aktaralım:
from sklearn.datasets import load_iris
import pandas as pd
import numpy as np
import seaborn as sns
Bu kütüphaneler, veri işleme ve görselleştirme için gereklidir.
Daha sonra, Scikit-learn'den Iris veri setini yükleyelim:
iris = load_iris()
Bu veri seti, iris çiçeklerinin çeşitli özelliklerine dayanan bir sınıflandırma problemi için kullanılır.
Veri setinin anahtarlarını inceleyelim:
iris.keys()
dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names', 'filename', 'data_module'])
Bu anahtarlar, veri setinin farklı bileşenlerine erişim sağlar.
Veri setinin açıklamasını yazdıralım, bu bölüm veri seti hakkında genel bilgiler içerir:
print(iris.DESCR)
Bu bölüm, veri setinin özellikleri, istatistiksel özetleri ve kaynak bilgilerini içerir.
Veri setinin ilk beş örneğini ve hedef değerlerini inceleyelim:
print(f"data: \n{iris.data[:5,:]}\n"
f"target: {iris.target[:5]}\n"
f"target_names: {iris.target_names[:5]}\n"
f"feature_names: {iris.feature_names}")
Bu kod bloğu, veri setinin yapısını ve örnek özellik değerlerini gösterir.
Hedef değişkenin belirli bir aralıktaki değerlerini gözlemleyelim:
iris.target[100:150]
Bu komut, hedef değişkenin 100 ile 150 arasındaki değerlerini döndürür.
Veri setinin ilk beş örneğine daha yakından bakalım:
iris.data[:5,:]
Bu, veri setinin ilk beş satırını ve tüm sütunlarını görüntüler.
Şimdi veriyi bir Pandas DataFrame'e dönüştürelim ve ilk beş örneğini gösterelim:
data = pd.DataFrame(iris.data, columns=iris.feature_names)
data.head()
Bu, oluşturulan DataFrame'in ilk beş satırını gösterir, her bir satır bir çiçek örneğini ve her bir sütun bir özelliği temsil eder.
Veri setinin son beş örneğini inceleyelim:
data.tail()
Bu, DataFrame'in son beş satırını görüntüler.
DataFrame'in boyutunu öğrenmek için:
data.shape
(150, 4) döner, bu da veri setinde 150 örnek ve dört özellik olduğunu gösterir.
Son olarak, hedef değişkenin isimlerini yazdıralım:
iris.target_names
Bu komut, hedef sınıfların isimlerini döndürür: ['setosa', 'versicolor', 'virginica'].
Bu adımlar, veri ön işleme sürecinin temel bileşenlerini oluşturur ve veri setinin daha derinlemesine analizi ve makine öğrenimi modellerinin eğitimi için temel hazırlar.
Veri Ön İşleme Adımları
Veri ön işleme, veri bilimi ve makine öğrenimi uygulamalarında temel bir adımdır. Bu süreç, verileri analiz ve modelleme için uygun hale getirir. İşlem kapsamında eksik veri doldurma, gürültülü veri temizleme ve veri standardizasyonu gibi görevler yer alır.
Bu bölümde, Scikit-learn kütüphanesinde bulunan popüler Iris veri seti üzerinde temel veri ön işleme adımlarını ele alacağız.
Veri Setinin Yüklenmesi
Veri setini Scikit-learn kütüphanesi üzerinden yükleyerek başlayalım:
from sklearn.datasets import load_iris
iris = load_iris()
Yüklenen veri seti, iris çiçeğinin farklı türlerine ait çeşitli özellikleri içerir.
Veri Setinin Anahtarları
Veri setinin yapısını anlamak için, içerdiği anahtarları inceleyelim:
iris.keys()
dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names', 'filename', 'data_module'])
Her anahtar, veri setinin farklı bileşenlerine işaret eder.
Veri Seti Açıklaması
Veri setinin genel açıklamasına bakalım:
print(iris.DESCR)
Bu açıklama, veri setinin özellikleri, özellik bilgileri ve istatistiksel özetleri hakkında bilgi verir.
Veri Örneklerinin ve Hedef Değerlerin İncelenmesi
İlk beş veri noktasını ve hedef değerlerini görelim:
print(f"data: \n{iris.data[:5,:]}\n"
f"target: {iris.target[:5]}\n"
f"target_names: {iris.target_names}\n"
f"feature_names: {iris.feature_names}")
Bu, veri setinin yapısını ve içeriğini anlamamıza yardımcı olur.
Hedef Değerlerin Aralığı
Hedef değişkenin benzersiz değer aralığını inceleyelim:
range(len(iris.target_names))
Bu, hedef sınıfların sayısını ve aralığını gösterir: 0'dan 2'ye.
Veri Görselleştirme
Veri setinin farklı özelliklerini görselleştirerek, özellikler arası ilişkileri ve dağılımları inceleyebiliriz.
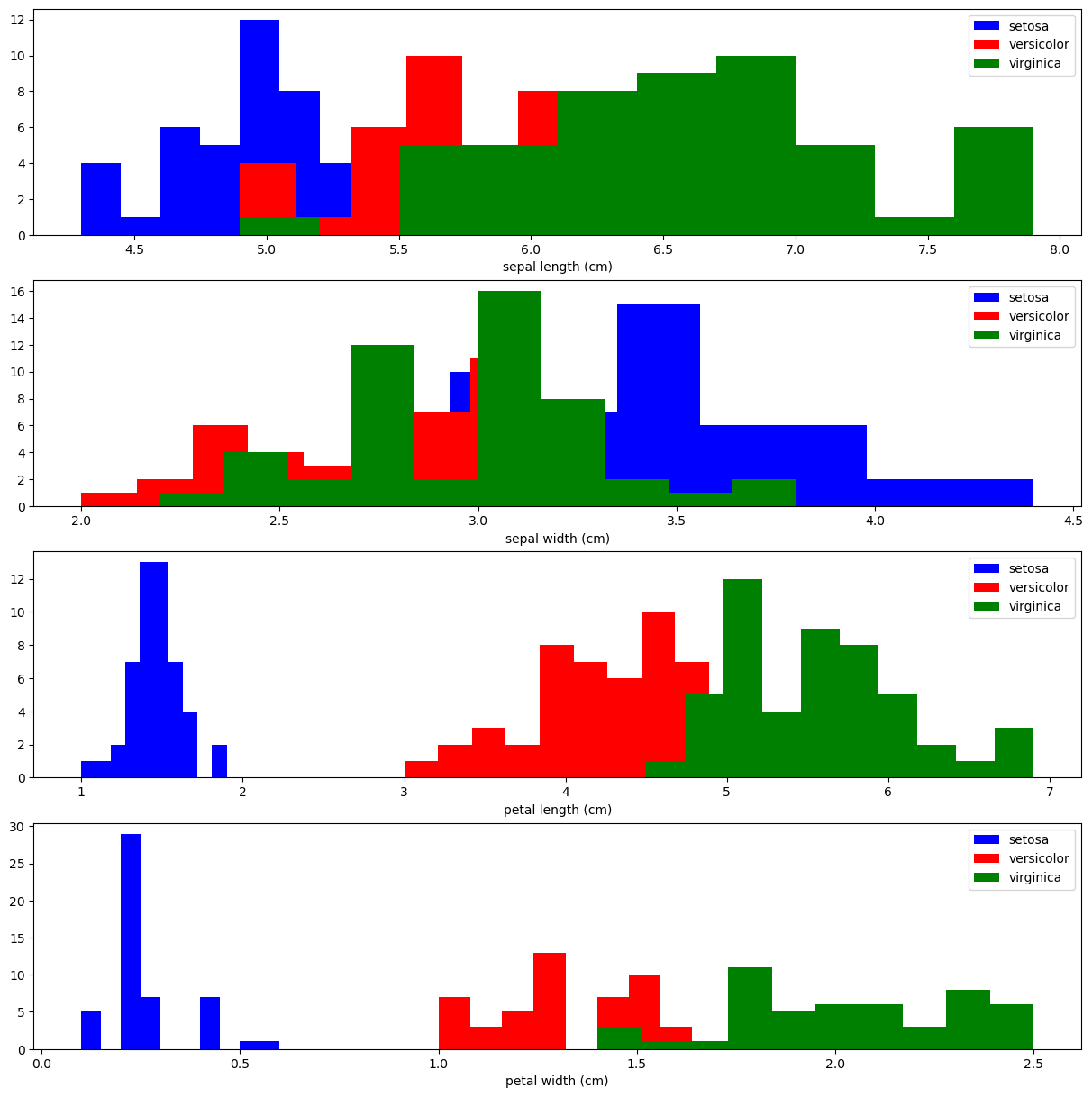
Özellik dağılımlarını görselleştirelim:
import matplotlib.pyplot as plt
fig, ax = plt.subplots(4, figsize=(15,15))
for x_index in range(4):
colors = ['blue', 'red', 'green']
for label, color in zip(range(len(iris.target_names)), colors):
ax[x_index].hist(iris.data[iris.target==label, x_index],
label=iris.target_names[label],
color=color)
ax[x_index].set_xlabel(iris.feature_names[x_index])
ax[x_index].legend(loc='upper right')
plt.show()
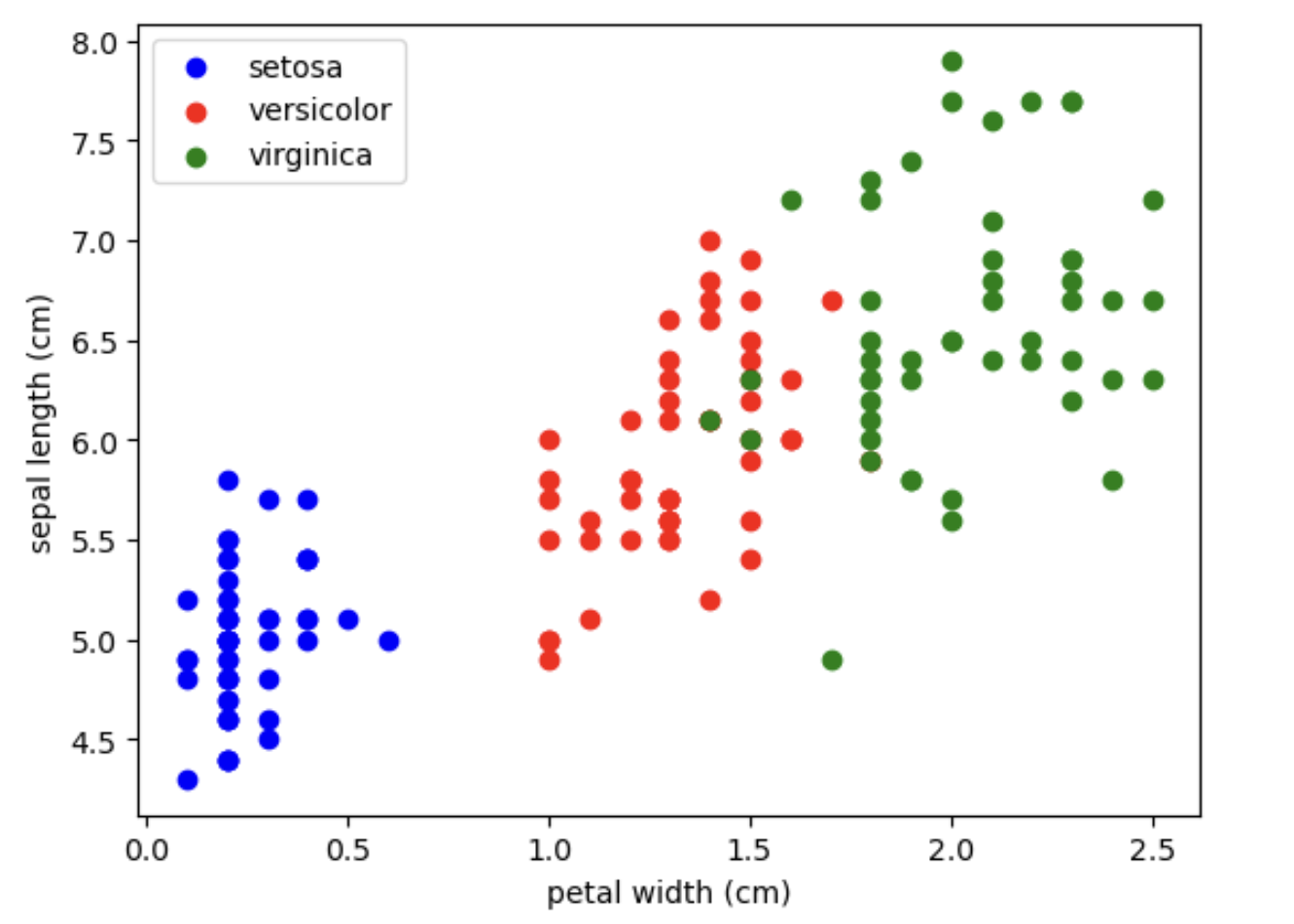
İki özellik arasındaki ilişkiyi görselleştirelim:
fig, ax = plt.subplots()
x_index = 3
y_index = 0
for label, color in zip(range(len(iris.target_names)), colors):
ax.scatter(iris.data[iris.target==label, x_index], iris.data[iris.target==label, y_index],
label=iris.target_names[label], c=color)
ax.set_xlabel(iris.feature_names[x_index])
ax.set_ylabel(iris.feature_names[y_index])
ax.legend(loc='upper left')
plt.show()
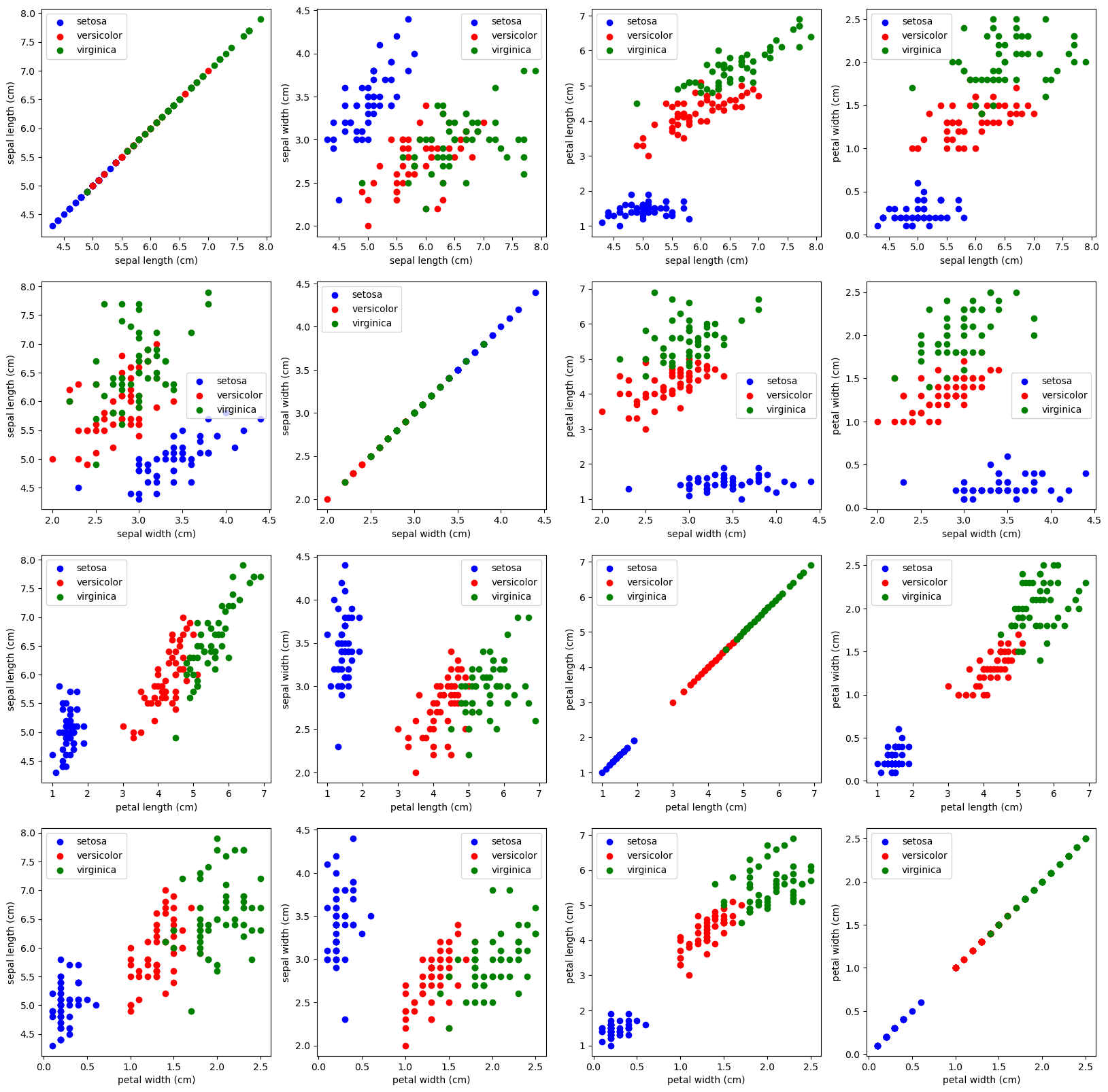
Dört özelliğin her birinin kombinasyonları arasındaki ilişkileri inceleyelim:
fig, ax = plt.subplots(4,4,
figsize=(20,20))
for x_index in range(4):
for y_index in range(4):
for label, color in zip(range(len(iris.target_names)), colors):
ax[x_index,y_index].scatter(iris.data[iris.target==label, x_index],
iris.data[iris.target==label, y_index],
label=iris.target_names[label], c=color)
ax[x_index,y_index].set_xlabel(iris.feature_names[x_index])
ax[x_index,y_index].set_ylabel(iris.feature_names[y_index])
ax[x_index,y_index].legend()
plt.show()
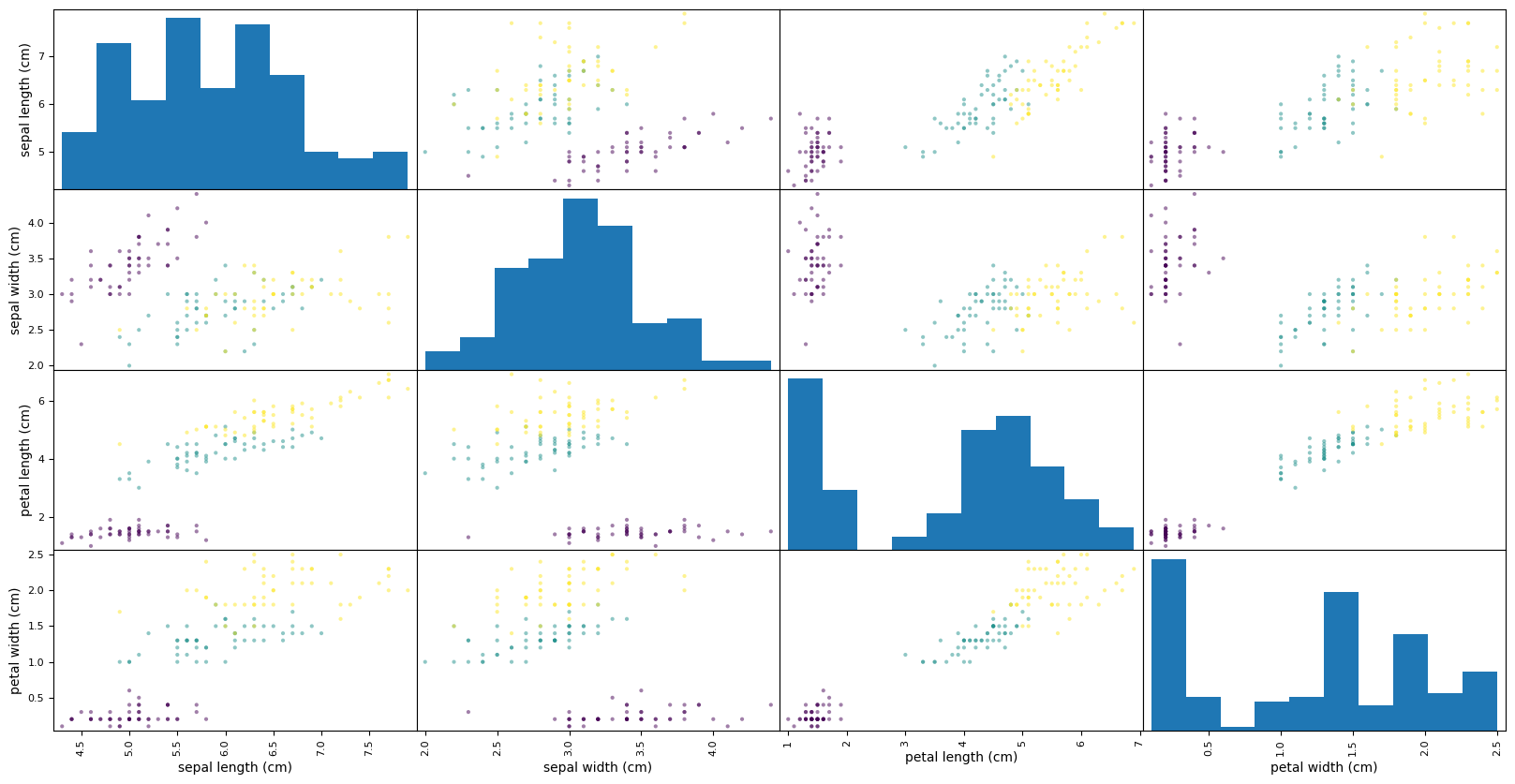
Pandas kütüphanesini kullanarak, scatter matrisi çizdirelim:
iris_df = pd.DataFrame(iris.data, columns=iris.feature_names)
pd.plotting.scatter_matrix(iris_df, c=iris.target, figsize=(20, 10))
Üç boyutlu görselleştirme ile veri setini farklı bir açıdan inceleyelim:
from mpl_toolkits.mplot3d import Axes3D
X = []
for iclass in range(3):
X.append([[], [], []])
for i in range(len(iris.data)):
if iris.target[i] == iclass:
X[iclass][0].append(iris.data[i][0])
X[iclass][1].append(iris.data[i][1])
X[iclass][2].append(sum(iris.data[i][2:]))
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
for iclass in range(3):
ax.scatter(X[iclass][0], X[iclass][1], X[iclass][2], c=colours[iclass])
plt.show()
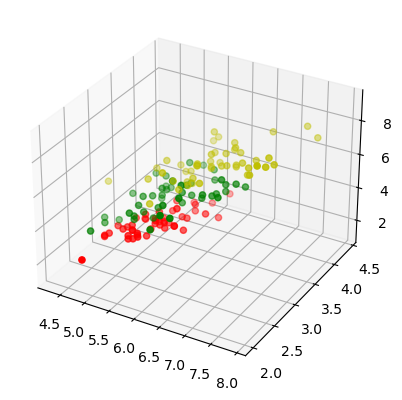
Eksik Veri Kontrolü ve Doldurma
Veri setindeki eksik değerleri kontrol edelim ve dolduralım:
data.isnull().sum()
Bu, her bir özellik için eksik veri sayısını gösterir.
Eksik verileri belirli bir strateji ile dolduralım (örneğin, ortalamayla):
data["sepal length (cm)"][:2] = np.nan
data.fillna(data.mean(), inplace=True)
Son olarak, eksik verilerin doldurulduğunu doğrulayalım:
data.isnull().sum()
Bu, tüm eksik değerlerin doldurulduğunu onaylar.
Veri setinin istatistiksel özetine bakalım:
data.describe()
Bu, veri setinin özet istatistiklerini gösterir ve verilerin genel dağılımını anlamamızı sağlar.
Bu bölümde, veri setlerini inceleme ve ön işleme teknikleri üzerinde durulmaktadır. Öncelikle, temel istatistiksel değerlere bakarak verilerin genel bir özetini elde edeceğiz.
Veri Özeti
Aşağıda verilen tablo, bir çiçek türü veri setinin temel istatistiksel özetini içermektedir. Bu özet, veri setinin her bir özelliğinin (feature) dağılımı hakkında bilgi sağlar.
| Özellik | Toplam Sayı | Ortalama | Standart Sapma | Min | 25% | 50% | 75% | Max |
|---|---|---|---|---|---|---|---|---|
| Sepal Uzunluğu (cm) | 150.000000 | 5.854730 | 0.822122 | 4.3 | 5.1 | 5.8 | 6.4 | 7.9 |
| Sepal Genişliği (cm) | 150.000000 | 3.057333 | 0.435866 | 2.0 | 2.8 | 3.0 | 3.3 | 4.4 |
| Petal Uzunluğu (cm) | 150.000000 | 3.758000 | 1.765298 | 1.0 | 1.6 | 4.35 | 5.1 | 6.9 |
| Petal Genişliği (cm) | 150.000000 | 1.199333 | 0.762238 | 0.1 | 0.3 | 1.3 | 1.8 | 2.5 |
Bu özeti inceleyerek, veri setinin çeşitli özelliklerinin dağılımı hakkında genel bir fikir edinebiliriz.
Veri Görselleştirme
Verilerin korelasyon matrisi aşağıda gösterilmektedir. Bu matris, veri özellikleri arasındaki ilişkilerin görselleştirilmesine yardımcı olur.
corr = data.corr()
plt.figure(figsize=(14, 14))
ax = sns.heatmap(
corr,
vmin=-10, vmax=10, center=0,
cmap=sns.diverging_palette(20, 220, n=200),
square=True, annot = True
)
ax.set_xticklabels(
ax.get_xticklabels(),
rotation=45,
horizontalalignment='right'
)
ax.set_ylim(len(corr)+0.5, -0.5);
Bu ısı haritası, değişkenler arasındaki ilişkilerin ne kadar güçlü olduğunu gösterir.
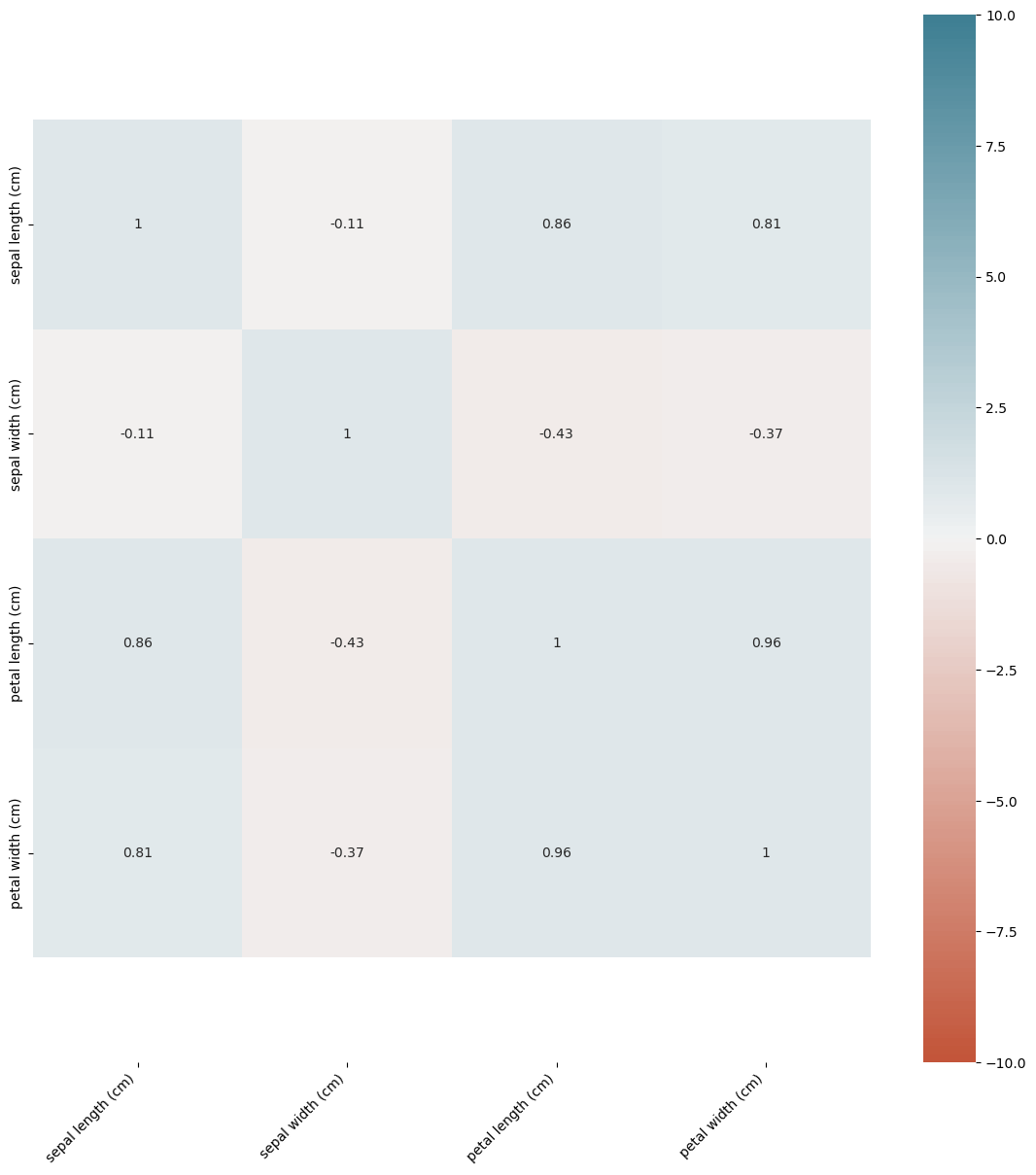
Veri Ön İşleme
Önişleme sırasında veri normalleştirme işlemi gerçekleştirilmiştir. Bu, veri aralığını [0,1] arasına çekerek tüm özellikleri aynı ölçeğe getirir.
from sklearn.preprocessing import MinMaxScaler
normalizer = MinMaxScaler()
data = normalizer.fit_transform(data)
Normalleştirmeden sonra ilk beş veri noktası aşağıdaki gibidir:
data[:5]
array([[0.43186937, 0.625 , 0.06779661, 0.04166667],
[0.43186937, 0.41666667, 0.06779661, 0.04166667],
[0.11111111, 0.5 , 0.05084746, 0.04166667],
[0.08333333, 0.45833333, 0.08474576, 0.04166667],
[0.19444444, 0.66666667, 0.06779661, 0.04166667]])
Ard
ından, özelliklerin normalleştirildikten sonra aldıkları minimum ve maksimum değerler kontrol edilir:
print(data.shape)
for i in range(4):
print(f"{i}. öznitelik sütunu minimum değeri: {min(data[:,i])}\n"
f"{i}. öznitelik sütunu maksimum değeri: {max(data[:,i])}\n")
(150, 4)
0. öznitelik sütunu minimum değeri: 0.0
0. öznitelik sütunu maksimum değeri: 1.0
- öznitelik sütunu minimum değeri: 0.0
- öznitelik sütunu maksimum değeri: 1.0
- öznitelik sütunu minimum değeri: 0.0
- öznitelik sütunu maksimum değeri: 1.0
- öznitelik sütunu minimum değeri: 0.0
- öznitelik sütunu maksimum değeri: 1.0
Etiket Kodlama
Etiket kodlama, kategorik verileri sayısal bir dizgeye dönüştürür. Aşağıdaki örnek, üç farklı kategoriyi ("a", "b", "c") sayısal değerlere dönüştürür.
from sklearn.preprocessing import LabelEncoder
labels_encoder = LabelEncoder()
data_encode1 = labels_encoder.fit_transform(["a","a","b","c","c","a"])
array([0, 0, 1, 2, 2, 0], dtype=int64)
Bu dizge, her bir kategorinin bir tam sayı değeri aldığını gösterir.
One-Hot Kodlama
One-hot kodlama, her kategoriyi benzersiz bir ikili vektöre dönüştürür. Bu, modelin kategorik verileri daha iyi işlemesine yardımcı olur.
from sklearn.preprocessing import OneHotEncoder
labels_encoder1 = OneHotEncoder()
data_encode2 = labels_encoder1.fit_transform(np.array(new_feature).reshape(-1,1))
array([[0., 0., 1.],
[1., 0., 0.],
[1., 0., 0.],
[1., 0., 0.],
...
[1., 0., 0.],
[1., 0., 0.],
[0., 1., 0.],
[1., 0., 0.]])
Bu matris, her satırın yalnızca bir kategoriyi temsil eden bir vektör olduğu bir yapıdır.
Veri setine one-hot kodlanmış kategorik özellikler eklenir:
data_last = np.hstack((data_new.iloc[:,:4], data_encode2.toarray()))
Yeni veri setinin ilk dört örneği:
data_last[:4,:]
array([['0.4318693693693698', '0.625', '0.06779661016949151',
'0.04166666666666667', 0.0, 0.0, 1.0],
['0.4318693693693698', '0.41666666666666674',
'0.06779661016949151', '0.04166666666666667', 1.0, 0.0, 0.0],
['0.11111111111111116', '0.5', '0.05084745762711865',
'0.04166666666666667', 1.0, 0.0, 0.0],
['0.08333333333333326', '0.45833333333333326',
'0.0847457627118644', '0.04166666666666667', 1.0, 0.0, 0.0]],
dtype=object)
Veri Bölme
Veri seti, modelin eğitimi ve testi için ayrılır. Bu, verinin %75'i eğitim için ve %25'i test için kullanılarak gerçekleştirilir:
from sklearn.model_selection import train_test_split
X, Y = data, iris.target
x_train, y_train, x_test, y_test = train_test_split(X, Y, train_size=0.75, random_state=42, shuffle=True)
Eğitim veri setinin boyutu:
x_train.shape
(112, 4)
Performans Metrikleri
Regrasyon modellerinin performansını değerlendirirken kullanılan çeşitli metrikler aşağıdaki gibi hesaplanır:
import numpy as np
from sklearn.metrics import mean_absolute_error, mean_squared_error, median_absolute
_error
gercek = [2, 4, 3]
tahmin = [1, 3, 5]
print("MAE=%0.2f" % mean_absolute_error(gercek, tahmin))
print("MSE=%0.2f" % mean_squared_error(gercek, tahmin))
print("MedAE=%0.2f" % median_absolute_error(gercek, tahmin))
print("RMSE=%0.2f" % np.sqrt(mean_squared_error(gercek, tahmin)))
MAE=1.33
MSE=2.00
MedAE=1.00
RMSE=1.41
Yapay Veri Seti Oluşturma
Makine öğrenimi algoritmalarını test etmek için yapay veri setleri oluşturabiliriz:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
# Veri setini oluştur
X, y = make_blobs(n_samples=200, n_features=3, centers=5, random_state=1, cluster_std=5)
# Veri setini görselleştir
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
ax.scatter(X[:, 0], X[:, 1], X[:, 2], c=y)
ax.set_xlabel('Özellik 1')
ax.set_ylabel('Özellik 2')
ax.set_zlabel('Özellik 3')
plt.show()

from sklearn.datasets import make_blobs
from matplotlib import pyplot
from pandas import DataFrame
# generate 2d classification dataset
X, y = make_blobs(n_samples=100, centers=3, n_features=2, cluster_std=1)
# scatter plot, dots colored by class value
df = DataFrame(dict(x=X[:,0], y=X[:,1], label=y))
colors = {0:'red', 1:'blue', 2:'green'}
fig, ax = pyplot.subplots()
grouped = df.groupby('label')
for key, group in grouped:
group.plot(ax=ax, kind='scatter', x='x', y='y', label=key, color=colors[key])
pyplot.show()
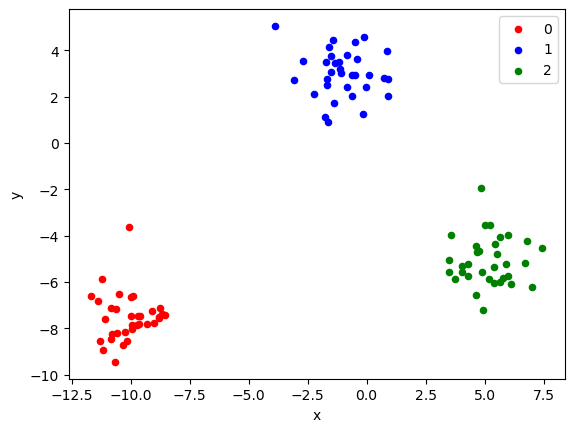
Burada, bir numpy dizisi kullanarak temel veri analizi işlemleri yapılmaktadır. İlk olarak, 100 ile 200 arasında rastgele tam sayılardan oluşan 1x10 boyutunda bir dizi oluşturulmuştur. Ardından, bu dizinin elemanlarının ortalaması, boyutu, toplamı ve tekrar hesaplanan ortalaması belirlenmiştir. İşte bu adımların detaylı bir açıklaması:
Veri Oluşturma ve Analiz
Veri Oluşturma:
100 ile 200 arasında rastgele sayılardan oluşan 1x10 boyutlarında bir numpy dizisi oluşturulur.
import numpy as np
data = np.random.randint(100, 200, size=(1, 10))Veri Gösterimi:
Oluşturulan dizi gösterilir:
dataarray([[190, 118, 107, 103, 184, 174, 177, 103, 159, 184]])
Ortalama Hesaplama:
Dizinin ortalaması numpy kütüphanesinin
meanfonksiyonu ile hesaplanır:np.mean(data)149.9
Veri Boyutu:
Dizinin boyutu sorgulanır:
data.shape(1, 10)
Manuel Toplam Hesaplama:
Dizinin tüm elemanları üzerinden döngü ile toplam hesaplanır:
toplam = 0
for i in data[0]:
toplam += iToplamın Gösterimi:
Hesaplanan toplam gösterilir:
toplam1499
Manuel Ortalama Hesaplama:
Elde edilen toplam değer üzerinden ortalama hesaplanır:
mean = toplam / 10Ortalamanın Gösterimi:
Hesaplanan ortalama gösterilir:
mean149.9